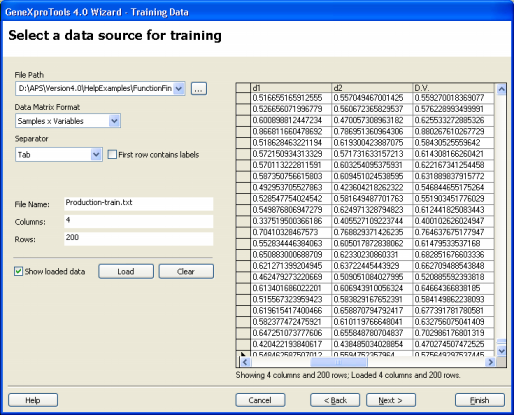
| Before evolving a model with GeneXproTools 4.0 you must first load the input data for the learning algorithm.
GeneXproTools 4.0 allows you to work either with databases/Excel or text
files and, for text files, accepts two different data matrix formats. The first is the standard Samples x Variables format where samples are in rows and variables in columns, with the dependent variable occupying the rightmost position. In the small example below with five samples, PRODUCTION is the dependent variable and LABOR, MATERIAL, and CAPITAL are the dependent variables: LABOR MATERIAL CAPITAL PRODUCTION 0.88287491 0.70249262 0.64540872 0.73044339 0.76598265 0.59360711 0.62686264 0.64924032 0.64562062 0.56965563 0.53160265 0.58497820 0.72908206 0.58913859 0.52247179 0.62160041 0.50690655 0.23498841 0.42968111 0.36493144 And the second, is the Gene Expression Matrix format commonly used in DNA microarrays studies where samples are in columns and variables in rows, with the dependent variable occupying the topmost position. For instance, in Gene Expression Matrix format, the small dataset above corresponds to: PRODUCTION 0.73044339 0.64924032 0.5849782 0.62160041 0.36493144 LABOR 0.88287491 0.76598265 0.64562062 0.72908206 0.50690655 MATERIAL 0.70249262 0.59360711 0.56965563 0.58913859 0.23498841 CAPITAL 0.64540872 0.62686264 0.53160265 0.52247179 0.42968111 which is not visually very appealing, but of course very handy for datasets with a relatively small number of samples and thousands of variables. Note, however, that for Excel files this format is not supported and if your data is kept in this format in Excel, you must copy it to a text file so that it can be loaded into GeneXproTools. GeneXproTools uses the Samples x Variables format throughout and therefore all formats are automatically converted and shown in this format. GeneXproTools supports the standard separators (space, tab, comma, semicolon, and pipe) and detects them automatically. The use of labels to identify your variables is optional and GeneXproTools also detects automatically whether they are present or not. If you use them, however, you will be able to generate more intelligible code where each variable is identified by its name, by checking the Use Labels box in the Model Panel.
To Load Input Data for Modeling
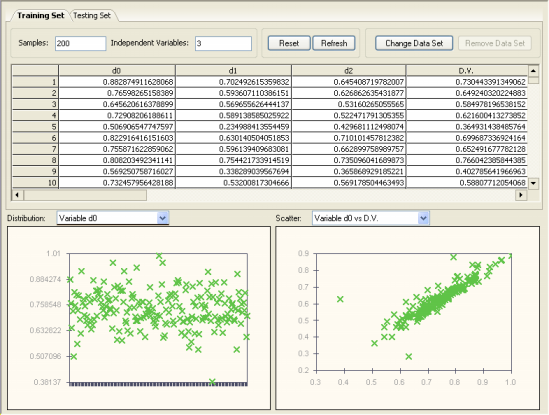
In data mining, be it performed by learning algorithms or conventional statistical methods, it really pays to take a good look at your data before embarking on a complex, usually time consuming modeling
process. It's true that evolutionary algorithms are particularly well equipped to deal with noisy data, but the better the data you feed them the better the models they produce.
The graphical visualization tools of GeneXproTools 4.0 make it easy to identify outliers, which may well represent errors in the data files. After loading your data into GeneXproTools, in the Data Panel you can visualize the distribution of values for each variable and also plot each independent variable against the dependent variable.
|